Learning Together to Perform Better: Teaching Small-Scale LLMs to Collaborate via Preferential Rationale Tuning
Abstract
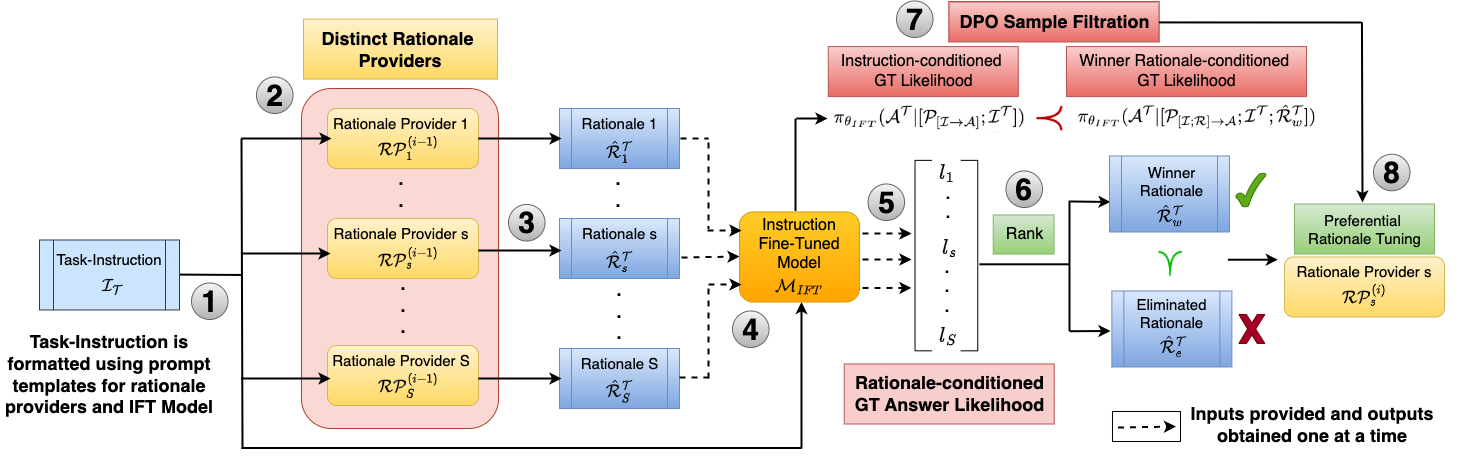
LLMs such as GPT-4 have shown a remarkable ability to solve complex questions by generating step-by-step rationales. Prior works have utilized this capability to improve smaller and cheaper LMs (say, with 7B parameters). However, various practical constraints, such as copyright and legal issues, owing to lack of transparency in the pre-training data of large (often closed) models, prevent their use in commercial settings. Little focus has been given to improving the innate reasoning ability of smaller models without distilling information from larger LLMs. To address this, we propose COLLATE, a trainable framework that tunes a (small) LLM to generate those outputs from a pool of diverse rationales that selectively improves the downstream task. COLLATE enforces multiple instances of the same LLM to exhibit distinct behavior and employs them to generate rationales to obtain diverse outputs. The LLM is then tuned via preference optimization to choose the candidate rationale which maximizes the likelihood of ground-truth answer. COLLATE outperforms several trainable and prompting baselines on 5 datasets across 3 domains - maths problem solving, natural language inference, and commonsense reasoning. We show the efficacy of COLLATE on LLMs from different model families across varying parameter scales (1B to 8B) and demonstrate the benefit of multiple rationale providers guided by the end task through ablations. Code is released here.